
Amazon SageMaker HyperPod で PyTorch による分散学習を試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Amazon SageMaker HyperPod で PyTorch による分散学習を実践した結果を紹介します。
今回のワークショップ
このワークショップでは、Slurm を使った HyperPod クラスターで大規模言語モデル (LLM) のトレーニングを体験できます。
本コンテンツの一部は re:Invent 2024 でワークショップとして開催された内容です。
本記事でお届けする内容
ワークショップのコンテンツを利用して、SageMaker HyperPod で PyTorch DDP(Distributed Data Parallel)を試してみました。本記事では、Slurm と PyTorch の設定に焦点を当てて解説します。
検証環境
HyperPod クラスター
ワークショップのコンテンツを利用して検証環境を構築しています。検証環境の構築手順は以下の記事をご参照ください。
クラスターの構成
- コントローラーノード: 1 台(ml.m5.large)
- ワーカーノード: 2 台(ml.c5.4xlarge)
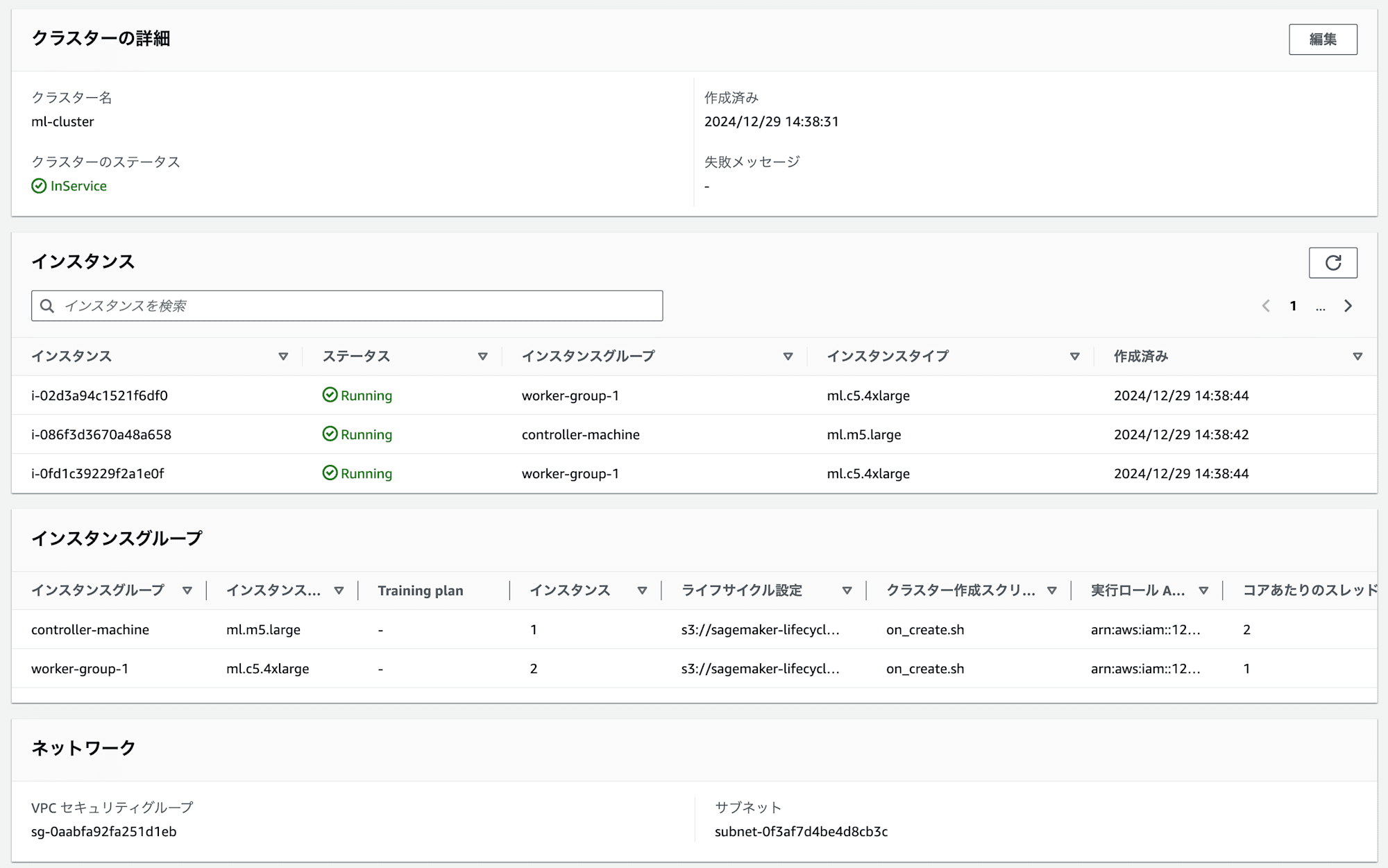
検証環境の状況
コントローラーノードへの接続
AWS Systems Manager のセッションマネージャーを使用してコントローラーノードに接続します。
CLUSTER_ID=jt52saf5imim
NODE_GROUP_NAME=controller-machine
INSTANCE_ID=i-086f3d3670a48a658
aws ssm start-session --target sagemaker-cluster:${CLUSTER_ID}_${NODE_GROUP_NAME}-${INSTANCE_ID}
クラスター状態の確認
ワーカーノードの CPU インスタンス 2 台は起動して待機中です。
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
dev* up infinite 2 idle ip-10-1-86-158,ip-10-1-120-53
ml.c5.4xlarge up infinite 2 idle ip-10-1-86-158,ip-10-1-120-53
PyTorch を使った分散学習
AWS が提供するワークショップの手順に沿って、conda を使用して Python 環境をセットアップしました。PyTorch による分散学習環境の構築から実行までを順を追って説明します。
環境構築に使用したジョブスクリプトは以下です。
Slurm の設定
PyTorch を利用した分散学習用のバッチジョブスクリプトについて、設定項目を確認していきます。
#!/bin/bash
#SBATCH --job-name=cpu-ddp-conda # ジョブ名を付ける
#SBATCH --exclusive # 他のジョブとノードを共有しない
#SBATCH --wait-all-nodes=1 # 1 を指定するとすぐに実行せずに全ノードが利用可能になるまで待機
#SBATCH --nodes 2 # 使用するノード数を指定
#SBATCH --output=logs/%x_%j.out # ログ出力設定(出力形式: [sbatch を実行時のカレントリディレクトリ]/logs/[ジョブ名]_[ジョブ ID].out)
wait-all-nodes=1は分散学習のノード間の同期を確実に取るためには必要そうですね。私が普段利用している ParallelCluster の場合は、--nodesで指定した台数のコンピュートノードが揃うまでジョブが実行されなく、明示的に指定しようと考えたことがありませんでした。
PyTorch の設定
PyTorch の分散学習のための設定を確認していきます。
declare -a TORCHRUN_ARGS=(
--nproc_per_node=4 # ノードごとのプロセス数
--nnodes=$SLURM_JOB_NUM_NODES # Slurmの変数から取得した総ノード数を指定(今回は 2 ノード)
--rdzv_backend=c10d # ランデブーを処理するために使用するバックエンドの指定
--rdzv_endpoint=$(hostname) # ランデブーのエンドポイント(ホスト名)の指定
)
--nproc_per_node=4は、今回 ml.c5.4large(物理 8 コア)のインスタンスを利用しているため、1 ノードあたり 8 プロセスまでは利用可能ではないかと疑問に思いました。ワークショップということもあり、他のプロセスのためにリソース確保して安定性を重視しているのではないかと推測します。考えられる理由としては、ワーカーノードへログインしてパフォーマンスモニタリングする工程が後ろに控えているため、リソースに余裕を持たせたかったのでしょう。
ランデブー(Rendezvous)という機能が PyTorch にあります。ワーカーノードでトレーニング開始/再開のタイミングを管理しています。ランデブーで利用する共有の KeyValue ストアがあり、KeyValue ストアで何を使うかの指定が--rdzv_backendです。c10dストアはデフォルト値ではないものの、一般的な設定値の様でした。
For most users this will be set to c10d (see rendezvous).
Train script — PyTorch 2.5 documentation
HyperPod の設定
HyperPod クラスターの特有の機能を説明します。srunコマンドの引数に--auto-resume=1を指定することで、ワーカーノードのハードウェア障害時に自動的に再開してくれます。マネージドサービスなので AWS 基板側の障害は HyperPod 側でなんとかできるようにオプション提供しておきますといった感じでしょうか。
if [ -d "/opt/sagemaker_cluster" ]; then
echo "Detected Hyperpod cluster.. enabling --auto-resume=1"
AUTO_RESUME="--auto-resume=1"
fi
srun ${AUTO_RESUME} ./pt_cpu/bin/torchrun \
"${TORCHRUN_ARGS[@]}" \
$(dirname "$PWD")/ddp.py 5000000 10
トレーニングサンプルスクリプト
参考: Distributed communication package - torch.distributed — PyTorch 2.5 documentation
線形学習させたモデルを作成します。
# モデルの定義部分
model = torch.nn.Linear(20, 1) # 20個の値の入力から1つの値を出力する線形モデル
入力データはランダムな値を生成して学習させています。特に意味のある出力結果を予測できるモデルではありませんでした。
# 入力データの生成
self.data = [(torch.rand(20), torch.rand(1)) for _ in range(size)]
分散 CPU トレーニング用のバックエンドglooを指定しています。今回は CPU でトレーニングする内容です。
def ddp_setup():
init_process_group(backend="gloo") # GPU 用は "nccl" を指定
こちらのddp.pyを実行するというと、Slurm を使い複数ノードで分散学習させます。1 つ前の Sbatch でサブミットするスクリプトの話に戻ります。引数にddp.py 5000000 10を指定してました。
学習するエポック(繰り返し)回数が 500 万を指しており、500 万回繰り返し学習します。10 エポックごとにモデルを保存する設定でした。後者はノードが停止したときの再開用途ですね。
srun ${AUTO_RESUME} ./pt_cpu/bin/torchrun \
"${TORCHRUN_ARGS[@]}" \
$(dirname "$PWD")/ddp.py 5000000 10
ジョブのサブミットと確認
ジョブをサブミットし、キューに追加されました。ワーカノードは常時起動しているためすぐに実行中(Status が Running)になっています。
$ sbatch 1.conda-train.sbatch
Submitted batch job 1
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST
1 dev cpu-ddp- ubuntu R 0:01 2 ip-10-1-86-158,ip-10-1-120-53
**マネージメントコンソールからでは、ワーカノードの CPU 使用率などパフォーマンスが一切わかりません。**ワーカーノードの 1 つにログインしてみます。
CLUSTER_ID=jt52saf5imim
NODE_GROUP_NAME=worker-group-1
INSTANCE_ID=i-0fd1c39229f2a1e0f
aws ssm start-session --target sagemaker-cluster:${CLUSTER_ID}_${NODE_GROUP_NAME}-${INSTANCE_ID}
htopの実行結果です。CPU 使用率は 46%です。プロセスの割り当て設定からすると 50%前後だと予想していたので想定どおりではあります。仮に 100%使い切っていたらログインしてhtopの結果を見られなかった可能性もあります。ワークショップとしては適切な判断でしょう。
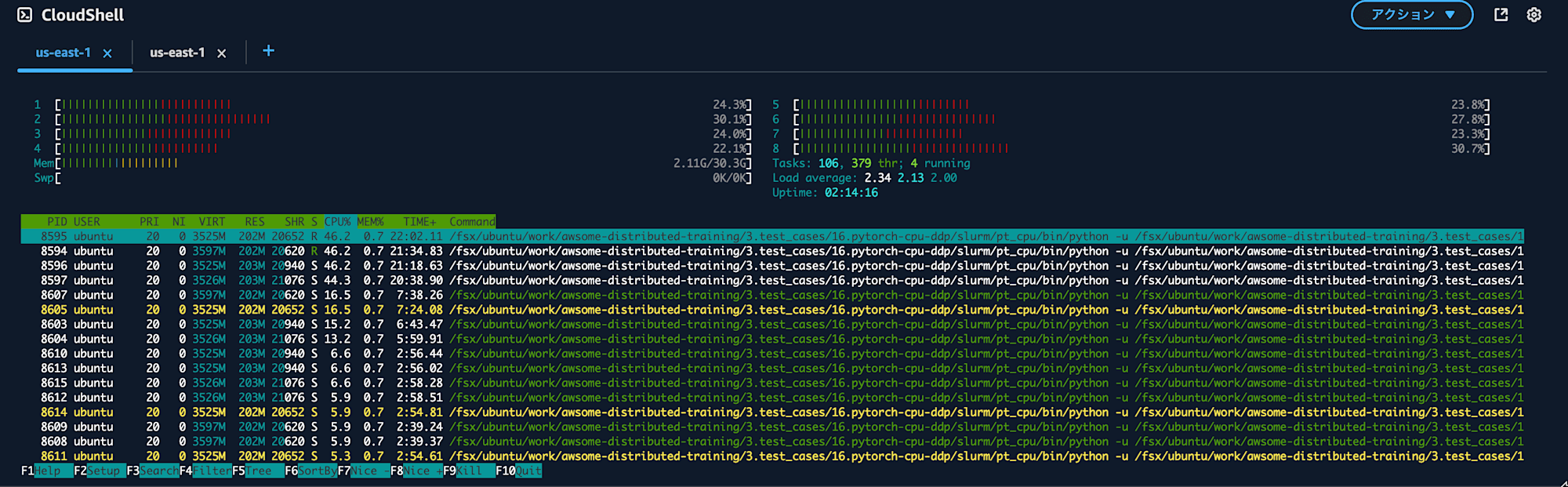
ml.c5.4xlarge を 2 台利用しているとはいえ、CPU 使用率は 50%程度なのでリソースを有効活用できていないので気長に完了を待ちます。
実行結果確認
1 日と 12 時間経過しましたがまだ終わりません。
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
11 dev cpu-ddp- ubuntu R 1-12:40:42 2 ip-10-1-86-158,ip-10-1-120-53
その 1 時間後には終わりました。実行ログの後半部分を抜粋しました。
[RANK 4] Epoch 4999999 | Batchsize: 32 | Steps: 8[RANK 6] Epoch 4999999 | Batchsize: 32 | Steps: 8
[RANK 7] Epoch 4999999 | Batchsize: 32 | Steps: 8
[RANK 3] Epoch 4999999 | Batchsize: 32 | Steps: 8
INFO:torch.distributed.elastic.agent.server.api:[default] worker group successfully finished. Waiting 300 seconds for other agents to finish.
INFO:torch.distributed.elastic.agent.server.api:Local worker group finished (SUCCEEDED). Waiting 300 seconds for other agents to finish
INFO:torch.distributed.elastic.agent.server.api:[default] worker group successfully finished. Waiting 300 seconds for other agents to finish.
INFO:torch.distributed.elastic.agent.server.api:Local worker group finished (SUCCEEDED). Waiting 300 seconds for other agents to finish
INFO:torch.distributed.elastic.agent.server.api:Done waiting for other agents. Elapsed: 0.0011348724365234375 seconds
INFO:torch.distributed.elastic.agent.server.api:Done waiting for other agents. Elapsed: 4.624900579452515 seconds
成果物は 1.2KB のsnapshot.ptです。PyTorch のスクリプト内で指定したあったモデル名が snapshot なので名前に違和感がありますが、機械学習が完了して出来上がったモデルがこちらです。
$ ls -lh snapshot.pt
-rw-rw-r-- 1 ubuntu ubuntu 1.2K Dec 30 20:16 snapshot.pt
HyperPod を利用した CPU トレーニングの実習が完了です。HyperPod はトレーニング向けのサービスのため、作成したモデルで推論するなら別の方法が必要になります。
まとめ
- HyperPod クラスターにより、分散学習環境を短時間で構築できました
- Slurm 設定と PyTorch DDP の連携ポイントを実践的に学べました
- CPU インスタンスでも分散学習が可能なことを確認できました
おわりに
他の AWS の HPC サービスにはなく、HyperPod 特有と感じられたのはハード障害時の自動復旧設定が用意されていたことでした。










